Chapitre II: Préparation des données
Sommaire
(Retour vers la page principale)
- Chapitre II: Préparation des données
II-1 Collection des données
II-1-1 Qualité des données
Critères d’intégrité des données:
- Taille: Nombre des échantillons (enregistrements). Certaines tâches nécessitent une grande taille de données pour qu’elles soient appris.
- Le nombre et le type de caractéristiques (nominales, binaires, ordinales ou continues).
- Le nombre des erreurs d’annotation
- La quantité de bruits dans les données: erreurs et exceptions
II-1-2 Intégration des données
Quand on veut collecter des données pour l’apprentissage automatique, souvent, on a besoin de combiner des données de différentes sources:
- Données structurées:
- Bases de données
- Fichiers de tabulateurs: CSV, etc.
- Données semi-structurées: XML, JSON, etc.
- Données non structurées: documents textes, images, métadonnées, etc.
Il faut, tout d’abord, vérifier l’intégrité des données:
- Vérifier que les fichiers XML sont conformes à leurs définitions XSD
- Vérifier que les séparateurs des colonnes dans les fichiers CSV sont correctes (point-virgule ou virgule et pas les deux au même temps).
Quand on joint deux schémas de données, on doit vérifier:
- Problème de nommage: il se peut qu’on ait des données identiques avec des nominations différentes. Par exemple, si on veut joindre deux tables de données b1 et b2 qui ont deux attributs avec le même sens mais différents noms b1.numclient et b2.clientid, on doit unifier les noms des attributs.
- Conflits de valeurs: les valeurs des attributs provenant de sources différentes sont représentées différemment. Par exemple, une source de données qui représente la taille en cm et une autre qui représente la taille en pouces.
- Redondance: les attributs qu’on puisse déduire des autres, les enregistrements identiques.
- Types différents des attributs
II-1-3 Annotation (Étiquetage) des données
L’annotation des données est la plus importante tâche dans l’apprentissage automatique. Si les données sont mal annotées, la performance de notre système d’apprentissage va diminuer. ImageNet (une base des images) a pris 9 années pour être annotée manuellement, avec un nombre de 14 millions images.
Approche 1: Annotation interne
Dans cette approche, on annote les données avec sa propre équipe.
Parmi ces avantages, on peut citer:
- Capacité à suivre le progrès: On peut vérifier le progrès de son équipe pour assurer qu’elle respecte le calendrier du projet.
- Bonne qualité: On peut vérifier la qualité de quelques données pendant l’annotation, identifier les annotateurs qui n’offrent pas une bonne qualité et guider la tâche en donnant des instructions sur les mauvais et les bons exemples qu’il faut suivre.
Les inconvénients:
- L’annotation est trop lente: si on gagne de la qualité, on va perdre du temps.
En résumé, si vous êtes une entreprise qui a suffisamment de ressources humaines, financières et du temps, cette approche est la votre.
Approche 2: L’externalisation (Outsourcing)
Si on ne dispose pas d’une équipe qualifiée pour l’annotation (pourtant l’annotation n’exige pas une grande expertise) ou on n’a pas assez de ressources humaines, on peut embaucher des travailleurs indépendants (freelancers).
- Préparer les données et fixer le temps exigé pour les annoter
- Diviser les sur des sous ensembles en supposant que ce temps est suffisant pour qu’une personne puisse terminer l’annotation d’un sous-ensemble
- publier des offres d’emploi sur les médias sociaux (LinkedIn par exemple)
Les avantages de cette approche:
- On sait ceux qu’on a embauché: On peut vérifier leurs compétences à l’aide de tests et on peut contrôler leur travail.
Les inconvénients de cette approche:
- On doit préparer des instructions détaillée sur le processus d’annotation pour que les annotateurs puissent comprendre comment faire la tâche correctement.
- On aura besoin de plus de temps pour soumettre et vérifier les tâches terminées.
- On doit créer un flux de travail: une interface qui aide les annotateurs.
Approche 3: Crowdsourcing
Si on ne veut pas gaspiller plus de temps pour recruter des gens et suivre leurs travaux, on peut toujours utiliser des plateformes de crowdsourcing. Ce sont des plateformes qui gèrent un grand nombre de contracteurs offrant la main d’œuvre à la demande. ils offrent des interfaces graphiques simples à utiliser pour créer des tâches d’annotation. Parmi les plateformes, on peut citer: Amazon Mechanical Turk (MTurk) et Clickworker.
Les avantages:
- Des résultats rapides
- Coûts abordables
Les inconvénients:
- La qualité des annotations: lorsque le revenu quotidien dépend du nombre de tâches accomplies, les gens essayent de terminer le plus nombre possible de tâche. Les plateformes de crowdsourcing utilisent des mesures de gestion de la qualité pour faire face à ce problème.
- On doit préparer des instructions détaillée sur le processus d’annotation pour que les annotateurs puissent comprendre comment faire la tâche correctement.
Il y a deux types de crowdsourcing:
- Explicite: En demandant directement des contributions
- Implicite: En intégrant des tâches dans d’autres formes afin de motiver la participation
- Tâches inévitables (par exemple, reCAPTCHA)
- Jeux ayant des objectifs (par exemple, jeu ESP)
Approche 4: Données synthétiques
Cette approche consiste à générer des données qui imitent les données réelles en termes de paramètres essentiels définis par un utilisateur. Les données synthétiques sont produites par un modèle génératif construit et validé sur un jeu de données original. Par exemple, générer des visages pour la reconnaissance faciale.
Les avantages:
- Gain de temps et de couts
- L’utilisation de données non sensibles: parfois, il faut demander la permission pour utiliser certaines données.
Les inconvénients:
- La nécessité pour le calcul haute performance
- Problèmes de qualité des données: Les données synthétiques peuvent ne pas ressembler aux données réelles.
Approche 5: Par programmation
Cette approche consiste à écrire des programmes qui annotent les données automatiquement. Le problème, ici, est qu’on a pu écrire une fonction pour annoter automatiquement les données. A quoi, donc, sert l’apprentissage automatique si notre système va apprendre cette même fonction?! En général, on peut utiliser cette approche pour enrichir les données (ajouter plus d’échantillons).
Par exemple, on peut utiliser un algorithme de regroupement (clustering) pour avoir des groupes; ensuite, on annote quelques échantillons dans chaque groupe et on généralise.
Les avantages:
- Moins d’annotation manuelle
Les inconvénients:
- précision faible des étiquettes
II-2 Nettoyage des données
Les problèmes rencontrés dans les données peuvent être:
- Valeurs omises (données non disponibles): des échantillons (enregistrements) avec des caractéristiques (attributs) sans valeurs. Les causes, entre autres, peuvent être:
- Mauvais fonctionnement de l’équipement
- Incohérences avec d’autres données et donc supprimées
- Non saisies car non (ou mal) comprises
- Considérées peu importantes au moment de la saisie
-
Échantillons dupliqués
- Des mauvaises annotations. Par exemple, un annotateur humain marque un échantillon comme “chat” or l’étiquette correcte est “chien”.
- Incohérence dans les conventions de nommage
- Bruit dans les données. Parmi ces causes:
- Instrument de mesure défectueux
- Problème de saisie
- Problème de transmission
Pour régler ces problèmes:
- Valeurs omises:
- Suppression
- Saisie manuelle
- Remplacement par une constante globale. Par exemple, “inconnu” pour les valeurs nominales ou “0” pour les valeurs numériques.
- Remplacement par la moyenne dans le cas des valeurs numériques, en préférence de la même classe.
- Remplacement par la valeur la plus fréquente dans le cas des valeurs nominales.
- Remplacement par la valeur la plus probable.
- Échantillons dupliqués
- Suppression
- Bruit (erreur ou variance aléatoire d’une variable mesurée):
- Binning ou Bucketing (groupement des données par classe). Consulter “Transformation des données”.
- Clustering pour détecter les exceptions
- Détection automatique des valeurs suspectes et vérification humaine.
- Lisser les données par des méthodes de régression.
II-3 Transformation des données
II-3-1 Discrétisation en utilisant le groupement (binning, bucketing)
La discrétisation est le fait de convertir les caractéristiques numériques en caractéristiques nominales. Elle est utilisée pour simplifier l’exploitation des données dans certains types d’algorithmes.
- Dans le classifieur naïf bayésien multinomial, les attributs doivent avoir des valeurs nominales.
- Certaines caractéristiques numériques sont utiles pour estimer une tâche, mais il n’existe aucune relation linéaire entre ces caractéristiques et cette tâche.
Prenant un exemple sur les prix des maisons suivant le latitude. On ne peut pas trouver une fonction linéaire entre le latitude et le prix d’une maison, mais on sait que l’emplacement où cette maison se trouve affecte son prix.
 |
|---|
| Exemple sur les prix des maisons [ Source ] |
On peut diviser la plage de latitude sur 11 parties (si on veut plus de précision, on peut augmenter le nombre des parties).
 |
|---|
| Binning de latitude avec des plages égales [ Source ] |
Donc, pour la caractéristique “latitude” les valeurs vont être représentée par une étiquette entre 1 et 11. Par exemple,
latitude 37.4 => 6
Dans le cas des algorithmes où on doit manipuler des valeurs numériques (comme les réseaux de neurones), on peut représenter chaque valeur comme un vecteur de 11 booléens (0 ou 1). Par exemple:
latitude 37.4 => [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
Dans certaines cas, diviser la plage d’une caractéristique en parties égales n’ai pas la bonne solution. Supposant, nous avons un ensemble de données sur le nombre des automobiles vendues pour chaque prix.
 |
|---|
| Binning des prix des automobiles avec des plages identiques [ Source ] |
On remarque qu’il y a un seul échantillon pour les prix > 45000. Pour fixer ça, on peut utiliser les quantiles: on divise notre jeu de données en intervalles contenant le même nombre de données.
 |
|---|
| Binning des prix des automobiles par quantiles [ Source ] |
II-3-2 Normalisation
Mise à l’échelle min-max
La mise en échelle min-max transforme chaque valeur numérique x vers une autre valeur x’ ∈ [0,1] en utilisant la valeur minimale et la valeur maximale dans les données. Cette normalisation conserve la distance proportionnelle entre les valeurs d’une caractéristique.
La mise à l’échelle min-max est un bon choix si ces deux conditions sont satisfaites:
- On sait les les limites supérieure et inférieure approximatives des valeurs de la caractéristique concernée (avec peu ou pas de valeurs aberrantes).
- Les valeurs sont presque uniformément réparties sur cette plage ( [min, max]).
Un bon exemple est l’âge. La plupart des valeurs d’âge se situent entre 0 et 90, et qui sont distribuées sur toute cette plage.
En revanche, utiliser cette normalisation sur le revenu est une mauvaise chose. Un petit nombre de personnes ont des revenus très élevés. Si on applique cette normalisation, la plupart des gens seraient réduits à une petite partie de l’échelle.
Cette normalisation offre plus d’avantages si les données se consistent de plusieurs caractéristiques. Ses intérets sont les suivants:
- Aider l’algorithme du gradient (un algorithme d’optimisation) à converger plus rapidement.
- Eviter le problème des valeurs non définies lorsqu’une valeur dépasse la limite de précision en virgule flottante pendant l’entraînement.
- Apprendre les poids appropriés pour chaque caractéristique; si une caractéristique a un intervalle plus large que les autres, le modèle généré va favoriser cette caractéristique.
Coupure
S’il existe des valeurs aberrantes dans les extrémités d’une caractéristique, on applique une coupure max avec une valeur α et/ou min avec une valeur β.
Par exemple, dans le graphe suivant, qui illustre le nombre de cambres par personnes, on remarque qu’au delà de 4 les valeurs sont très baisses. La solution est d’appliquer une coupure max de 4.
 |
|---|
| Nombre de chambres par personne: avant et après la coupure avec max de 4 personnes [ Source ] |
Mise à l’échelle log
Cette transformation est utile lorsque un petit ensemble de valeurs ont plusieurs points, or la plupart des valeurs ont moins de points. Elle sert à compresser la range des valeurs.
Par exemple, les évaluations par film. Dans le schéma suivant, la plupart des films ont moins d’évaluations.
 |
|---|
| Normalisation log des évaluation des films [ Source ] |
Z-score
Le Z-score est utilisé pour assurer que la distribution d’une caractéristique ait une moyenne = 0 et un écart type = 1. C’est utile quand il y a quelques valeurs aberrantes, mais pas si extrême qu’on a besoin d’appliquer une coupure. Dans certaines ouvrages, cette transformation n’est pas classifiée comme une “normalisation” mais comme étant une “standardisation”. Cela est due au fait qu’elle transforme l’ancienne distribution à une distribution normale.
Étant donnée une caractéristique avec des valeurs x, les nouvelles valeurs x’ peuvent être exprimer par x, la moyenne des valeurs μ et leurs écart type σ.
II-3-3 Binarisation
Il existe des cas où on n’a pas besoin des fréquences (nombre d’occurrences) d’une caractéristique pour créer un modèle; on a besoin seulement de savoir si cette caractéristique a apparue une fois au moins pour un échantillon. Dans le cas général, on veut vérifier si la fréquence a dépassé un certain seuil a ou non. Dans ce cas, on binarise les valeurs de cette caractéristique.
Par exemple, si on veut construire un système de recommandation de chansons, on va simplement avoir besoin de savoir si une personne est intéressée ou a écouté une chanson en particulier. Cela n’exige pas le nombre de fois qu’une chanson a été écoutée mais, plutôt, les différentes chansons que cette personne a écoutées.
II-3-4 Créations de nouvelles caractéristiques (Les interactions)
Dans l’apprentissage automatique supervisés, en général, on veut modéliser la sortie (classes discrètes ou valeurs continues) en fonction des valeurs de caractéristiques en entrée. Par exemple, une équation de régression linéaire simple peut modélise la sortie y en se basant sur les caractéristiques xi et leurs poids correspondants wi comme suit:
Dans ce cas, on a modélisé la sortie en se basant sur des entrées indépendantes l’une de l’autre. Cependant, souvent dans plusieurs scénarios réels, il est judicieux d’essayer également de capturer les interactions entre les caractéristiques. Donc, on peut créer de nouvelles caractéristiques en multipliant les anciennes deux à deux (ou encore plus). Notre équation de régression linéaire sera comme suit:
II-4 Échantillonnage et fractionnement des données
II-4-1 Données déséquilibrées
Dans la classification, les données d’entraînement peuvent avoir des classes avec des proportions asymétriques. Les classes qui constituent une grande (petite) proportion de données sont appelées classes majoritaires (minoritaires) respectivement. D’après le tutorial de Google, le degré de déséquilibre peut aller de léger à extrême, comme le montre le tableau suivant:
| degré de déséquilibre | Proportion de classe minoritaire |
|---|---|
| léger | 20-40% de données |
| modéré | 1-20% de données |
| extrême | <1% de données |
Par exemple, dans le cas de la détection de fraude, les cas positifs (il y a un fraude) sont rares par rapport au cas négatif (pas de fraude). On va finir par une distribution de données comme dans le schéma suivant (200 négatifs et 1 positif).
 |
|---|
| Exemple des données déséquilibrées pour la détection de fraudes [ Source ] |
Lors de la phase d’entrainement, le système va prendre plus de temps à apprendre le cas négatif (pas de fraude) que le cas positif. Même si on a ce problème, on essaye d’entrainer notre système. Si le modèle ne donne pas de bonnes résultats lors du test, on essaye de régler ça.
Sous-échantillonnage
Le sous-échantillonnage équilibre le jeu de données en réduisant la taille de la classe majoritaire. Cette méthode est utilisée lorsque la quantité de données est suffisante, donc on peut supprimer des échantillons de la classe majoritaire au hasard. Cela peut aider le système à converger rapidement et, aussi, préserver l’espace de stockage du modèle généré. Dans l’exemple précédent, on peut diminuer la taille des négatifs 10 fois pour avoir 20 échantillons.
 |
|---|
| Exemple d’un sous échantillonnage pour la détection de fraudes [ Source ] |
Pour calibrer le modèle, on peut donner un poids élevé aux scores générés par la classe sous-échantillonnée.
Sur-échantillonnage
Le sous-échantillonnage équilibre le jeu de données en augmentant la taille de la classe minoritaire. Cette méthode est utilisée lorsque la quantité de données est insuffisante. On peut augmenter la taille de la classe minoritaire en utilisant plusieurs techniques:
- Répétition: réplication aléatoire des échantillons de la classe minoritaire
- Techniques de bootstrap
- SMOTE (Synthetic Minority Over-Sampling Technique)
Ré-échantillonage en ensembles de données équilibrées
Dans ce cas, on peut créer plusieurs ensembles de données en divisant la classe majoritaire sur plusieurs ensemble et fusionnant la classe minoritaire avec chaque ensemble. Ensuite, on peut entrainer plusieurs modèles sur ces ensembles.
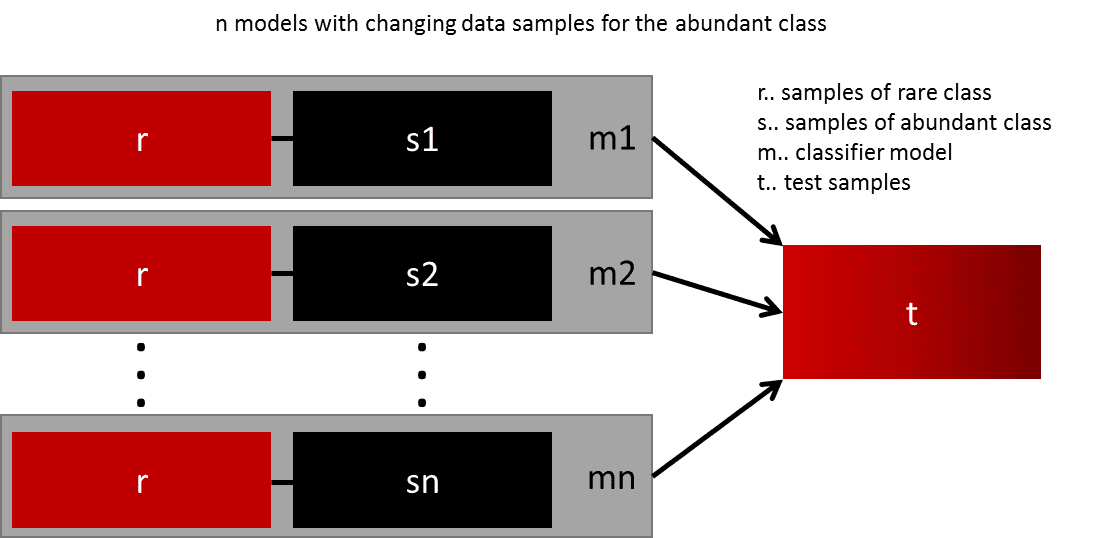 |
|---|
| Exemple ré-échantillonnage en ensembles de données équilibrées [ Source ] |
Ré-échantillonnage en ensembles de données avec ratios
On peut, aussi, créer plusieurs ensembles de données en jouant sur le ratio entre la classe minoritaire et la classe majoritaire. Ensuite, on peut entrainer plusieurs modèles sur ces ensembles.
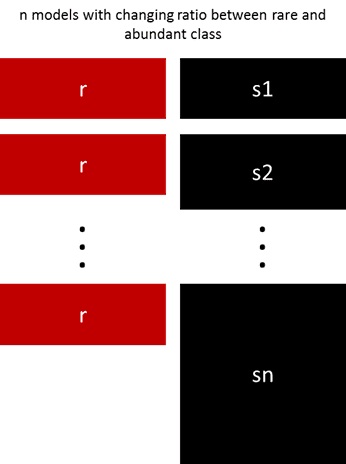 |
|---|
| Exemple ré-échantillonnage en ensembles de données avec ratios [ Source ] |
II-4-2 Fractionnement des données
Dans le cas d’apprentissage supervisé, il ne faut pas entrainer et tester votre modèle sur les mêmes données. Le système doit être tester sur des données qu’il n’a pas encore rencontré pour tester s’il a bien généralisé à partir des données qu’il a vu déjà. Donc, on a besoin de diviser notre ensemble de données sur deux sous-ensembles:
- Données d’entrainement avec une majorité des échantillons (70-80%)
- Données de test avec une minorité des échantillons (30-20%)
Lors du fractionnement, il faut prendre en considération ces deux conditions:
- Les données de test sont suffisantes pour avoir des résultats significatifs.
- Les données de test sont représentatives. Il ne faut pas prendre un ensemble avec des caractéristiques différentes de celles des données d’entrainement.
 |
|---|
| Exemple de fractionnement des données [ Source ] |
Parfois, lorsqu’on teste notre modèle et on rend compte qu’il donne des résultats médiocres, on veut refaire la phase d’entrainement en changeant les paramètres de notre système. En faisant ça plusieurs fois, notre modèle sera ajusté aux données de test. Pour faire face à ce problème, on peut créer un troisième ensemble pour la validation. Les processus d’apprentissage sera comme suit:
- Entrainer le système sur l’ensemble des données d’entrainement pour avoir un modèle
- Tester le modèle sur l’ensemble des données de validation
- Si la performance est bonne, aller vers l’étape suivante
- Sinon, changer les paramètres de votre système et refaire l’étape précédente
- Tester le modèle sur l’ensemble de test pour calculer la performance de votre système et comparer avec les autres systèmes existants.
II-5 Outils de préparation des données
Bibliothèques de programmation
| Outil | Licence | Langage |
|---|---|---|
| Encog | C#, Java | |
| Java Statistical Analysis Tool (JSAT) | GPL 3 | Java |
| pandas | BSD | Python |
| scikit-learn | BSD | Python |
Logiciels
- Alteryx designer Payant, Windows
- Rapidminer studio Freemium,
- Weka Licence GPL, Java
- Ce sont des logiciels visuels qui peuvent être utilisés par des non informaticiens.
- Orange3: écrit en python.
Services
II-6 Un peu de programmation
II-6-1 Lecture des données
Pour lire les données, on va utiliser la bibliothèque pandas. Elle support plusieurs types de fichiers: csv (read_csv), JSON (read_json), HTML (read_html), MS Excel (read_excel), SQL (read_sql), etc.
import pandas
Ici, on va utiliser l’ensemble des données Census Income Data Set (Adult). Les données se composent de 14 caractéristiques et de 48842 échantillons. Dans le but de l’exercice, on a réduit le nombre des caractéristiques à 7 et quelques échantillons dispersés sur plusieurs formats de fichiers.
Fichier adult1.csv
Le premier fichier (data/adult1.csv) est un fichier CSV avec des colonnes séparées par des virgules (50 échantillons). Le fichier contient les colonnes suivantes (avec l’entête: titres des colonnes) dans l’ordre:
- age: entier.
- workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked.
- education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool.
- Marital-status: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse.
- occupation: Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces.
- sex: Female, Male.
- Hours-per-week: entier.
- class: <=50K, >50K
On sait que le fichier est bien formé; donc, on ne va pas vérifier le format. On va ignorer les espaces qui suivent les séparateurs en utilisant l’option skipinitialspace.
adult1 = pandas.read_csv("../../data/adult1.csv", skipinitialspace=True)
Fichier adult2.csv
Le deuxième fichier est un fichier CSV lui aussi, mais les colonnes sont séparées par des points-virgules. Le fichier est mal-formé; il existe des lignes avec séparation par virgules. Aussi, il n’y a pas d’entête pour désigner les noms des colonnes (caractéristiques). Voici le sens des colonnes dans l’ordre:
- class: Y, N (il gagne plus de 50K)
- age: entier
- sex: F, M
- workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked.
- education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool.
- hours-per-week: entier.
- marital-status: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse.
Dans ce cas, on va créer une liste des noms des colonnes (noms) et l’assigner comme entête en utilisant l’option names. Aussi, il faut spécifier quil n’y a pas d’entête (la première ligne contient des données et pas les noms des colonnes) en utilisant l’option header=None. Le séparateur du fichier CSV peut être spécifié en utilisant l’option sep.
noms = ["class", "age", "sex", "workclass", "education", "hours-per-week", "marital-status"]
adult2 = pandas.read_csv("../../data/adult2.csv", skipinitialspace=True, sep=";", header=None, names=noms)
Pour plus d’options veuillez consulter la documentation de read_csv. Le problème qui se pose est qu’on va avoir des lignes avec des “NaN” (valeurs non définies). On va régler ça dans l’étape de nétoyage des données.
Fichier adult3.db (sqlite)
Le troisième fichier est de format Sqlite, dont le schéma est le suivant:
CREATE TABLE `income` (
`num` INTEGER, --identifiant
`age` INTEGER,
`workclass` TEXT,
`education` TEXT,
`marital-status` TEXT,
`sex` TEXT,
`hours-per-day` REAL,
`class` TEXT
);
Les valeurs possibles des champs (les valeurs non définies sont marquées par “?”):
- num: entier pour identifier l’individu
- age: entier
- workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked.
- education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool.
- marital-status: married, divorced, widowed, single.
- sex: F, M
- hours-per-day: réel; la moyenne des heurs pour chaque jour (supposant, on travaille 5 jours/semaine)
- class: Y, N
Pour lire les données d’une base de données, on va utiliser la méthode read_sql_query de pandas. L’SGBD peut être interrogé en utilisant le module sqlite3. Les valeurs “?” veulent dire “pas définies”. Pour être cohérent avec les données précédentes, on doit remplacer les “?” par la valeur “NaN” de numpy.
import sqlite3
import numpy
#établir la connexion avec la base de données
con = sqlite3.connect("../../data/adult3.db")
#récupérer le résultat d'une réquête SQL sur cette connexion
adult3 = pandas.read_sql_query("SELECT * FROM income", con)
#remplacer les valeurs "?" par NaN de numpy
adult3 = adult3.replace('?', numpy.nan)
Fichier adult4.xml
Le 4ième fichier est de format XML dont la DTD est la suivante:
<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT income (candidat)*>
<!ATTLIST candidat id ID #REQUIRED>
<!ELEMENT candidat (age, workclass, education, marital-status, sex, hours-per-week, class)>
<!ELEMENT age #PCDATA>
<!ELEMENT workclass #PCDATA>
<!ELEMENT education #PCDATA>
<!ELEMENT marital-status #PCDATA>
<!ELEMENT sex #PCDATA>
<!ELEMENT hours-per-week #PCDATA>
<!ELEMENT class #PCDATA>
- Les valeurs possibles des champs nominaux sont comme celles de la base de données sqlite (fichier adult3.db).
- Les valeurs non définies sont représentées par l’absence de leurs balises respectives dans le fichier XML.
Pour valider le fichier XML, on va utiliser la bibliothèque lxml.
from lxml import etree
#créer le parser et spécifier qu'il doit valider le DTD
parser = etree.XMLParser(dtd_validation=True)
#analyser le fichier XML en utilisant ce parser
arbre = etree.parse("../../data/adult4.xml", parser)
Après l’exécution de ces instructions nous avons eu le message d’erreur suivant
>> python preparer.py
Traceback (most recent call last):
File "preparer.py", line 29, in <module>
arbre = etree.parse("../../data/adult4.xml", parser)
File "src/lxml/etree.pyx", line 3426, in lxml.etree.parse
File "src/lxml/parser.pxi", line 1839, in lxml.etree._parseDocument
File "src/lxml/parser.pxi", line 1865, in lxml.etree._parseDocumentFromURL
File "src/lxml/parser.pxi", line 1769, in lxml.etree._parseDocFromFile
File "src/lxml/parser.pxi", line 1162, in lxml.etree._BaseParser._parseDocFromFile
File "src/lxml/parser.pxi", line 600, in lxml.etree._ParserContext._handleParseResultDoc
File "src/lxml/parser.pxi", line 710, in lxml.etree._handleParseResult
File "src/lxml/parser.pxi", line 639, in lxml.etree._raiseParseError
File "../../data/adult4.xml", line 51
lxml.etree.XMLSyntaxError: Element candidat content does not follow the DTD, expecting (age , workclass , education , marital-status , sex , hours-per-week , class), got (age education marital-status sex hours-per-week class ), line 51, column 12
Il est évident que le champs “workclass” n’existe pas dans un enregistrement. Le problème, ici, est que celui qui a créé ce fichier XML n’a pas respecté sa propre définition DTD. Il fallait qu’il crée des balises vides ou avec un symbole spécifique même si la valeur est absente. Pour traiter ça, on va modifier le fichier DTD afin qu’il accepte des éléments de moins.
<!ELEMENT candidat (age?, workclass?, education?, marital-status?, sex?, hours-per-week?, class)>
Pour traiter un nœud XML, on va définir une fonction qui retourne son texte s’il existe, sinon la valeur “NaN” de numpy.
def valeur_noeud(noeud):
return noeud.text if noeud is not None else numpy.nan
On crée un objet de type pandas.DataFrame avec les titres des colonnes. Ensuite, on parcourt les éléments un par un en ajoutant les valeurs dans l’objet qu’on a créé.
noms2 = ["id", "age", "workclass", "education", "marital-status", "sex", "hours-per-week", "class"]
adult4 = pandas.DataFrame(columns=noms2)
for candidat in arbre.getroot():
idi = candidat.get("id")
age = valeur_noeud(candidat.find("age"))
workclass = valeur_noeud(candidat.find("workclass"))
education = valeur_noeud(candidat.find("education"))
marital = valeur_noeud(candidat.find("marital-status"))
sex = valeur_noeud(candidat.find("sex"))
hours = valeur_noeud(candidat.find("hours-per-week"))
klass = valeur_noeud(candidat.find("class"))
adult4 = adult4.append(
pandas.Series([idi, age, workclass, education, marital, sex, hours, klass],
index=noms2), ignore_index=True)
II-6-2 Intégration des données
Lors de la lecture des 4 fichiers, on remarque que leurs schémas sont différents. Donc, avant de fusionner les 4 schémas, il faut régler les problèmes qui gênent à cette opération. Voici la liste des problèmes rencontrés:
- Ordre et noms différents des caractéristiques. Par exemple, le champs “class” est en dernier dans des schémas, et en premier dans d’autres.
- Renommer les caractéristiques
- Réorganiser l’ordre des caractéristiques dans les tableaux.
-
Problème d’échelle: dans la caractéristique “adult3.hours-per-day” qui est représetée par “hours-per-week” dans les autres schémas. On multiplie les valeurs par 5 (nous avons supposé 5 jours/semaines) et on renomme la colonne “hours-per-week”.
- Échantillons (enregistrement) redondants: les schémas de “adult3.db” et “adult4.xml” contiennent une caractéristique: “num” et “id” respectivement (qu’on a unifié dans l’étape précédente).
Ici, on ne veut pas qu’une personne se répète plus d’une fois.
- Supprimer une des deux échantillons redondants
- On remarque qu’il y a des échantillons dupliqués où un est plus complet (ne contient pas de valeurs manquantes) que l’autre. Donc, on garde le plus complet.
- Caractéristiques inutiles (de plus): adult1.csv contient la caractéristique “occupation” qui ne figure pas chez les autres fichiers.
- Supprimer la colonne
- Conflits de valeurs, les caractéristiques suivantes ont des différentes valeurs possibles entre les schémas (solution: unifier les valeurs).
- marital-status: on garde les valeurs les plus restreintes (married, divorced, widowed, single). Les autres valeurs seront transformées à une de ces 4.
- sex: on garde les valeurs avec moins de taille (F, M)
- class: on garde les valeurs avec moins de taille (Y, N)
Ordre et noms différents des caractéristiques
On commence par renommer les caractéristiques identiques.
- adult3.num sera adult3.id, pour être homogène avec adult4.id
- adult3.hours-per-day sera adult3.hours-per-week pour être homogène avec les autres schémas. On va transformer les valeurs après.
- adult1.Hours-per-week sera adult1.hours-per-week (un problème de majuscule)
- adult1.Marital-status sera adult1.marital-status (un problème de majuscule)
On va utiliser la méthode pandas.DataFrame.rename où l’objet “adult3” est de type pandas.DataFrame.
adult3.rename(columns={"num": "id", "hours-per-day": "hours-per-week"}, inplace=True)
adult1.rename(columns={"Hours-per-week": "hours-per-week", "Marital-status": "marital-status"}, inplace=True)
Ensuite, on va ordonner les caractéristiques selon cet ordre: “age”, “workclass”, “education”, “marital-status”, “sex”, “hours-per-week”, “class”. Les caractéristiques en plus vont être mises en derniers. On va utiliser la méthode pandas.DataFrame.reindex.
ordre = ["age", "workclass", "education", "marital-status", "sex", "hours-per-week", "class"]
adult1 = adult1.reindex(ordre + ["occupation"], axis=1)
#print adult1.head()
adult2 = adult2.reindex(ordre, axis=1)
adult3 = adult3.reindex(ordre + ["id"], axis=1)
adult4 = adult4.reindex(ordre + ["id"], axis=1)
Problème d’échelle
On a modifié “adult3.hours-per-day” par “hours-per-week” qui change le sens mais pas les valeurs. On va régler ça ici.
adult3["hours-per-week"] *= 5
On a réglé ce problème avant de régler la redondance, puisque dans l’étape suivante on va fusionner les deux tables “adult3” et “adult4”.
Echantillons (enregistrement) redondants
Les tables “adult3” et “adult4” contiennent des enregistrements avec le même “id”. Une solution est de fusionner les deux tables dans une seule (disant “adult34”), ensuite utiliser la méthode pandas.DataFrame.drop_duplicates. On peut choisir quelle occurence on veut garder.
adult34 = pandas.concat([adult3, adult4])
adult34 = adult34.drop_duplicates("id", keep="last")
Dans notre cas, il faut remplir les valeurs manquantes à partir des autres enregistrements identiques (le même “id”) avant de supprimer une des deux. L’idée est la suivante:
- On fusionne les deux tables
- On regroupe les enregistrements en se basant sur la caractéristique (champs, attribut, colonne) “id”.
- On fait un remplissage en arrière par groupe: la valeur “NaN” sera remplacée par une valeur
Après l’application de ces étapes, on a remarqué que cette approche n’a pas fonctionné.
On a essayé d’ordonner les enregistrements selon le “id” pour enquêter quelles sont les valeurs réglées; c’était un peu étrange: l’ordre n’était pas juste.
En affichant les types des colonnes en utilisant print adult34.dtypes, on a eu:
age object
workclass object
education object
marital-status object
sex object
hours-per-week object
class object
id object
dtype: object
Peut être en transformant le type de “id” en entier, le problème va se régler. L’idée, donc, sera:
# concaténer les enregistrements des deux tables
adult34 = pandas.concat([adult3, adult4], ignore_index=True)
# définir le type de "id" comme étant entier, et remplacer la colonne
adult34["id"] = pandas.to_numeric(adult34["id"], downcast="integer")
# ordonner les enregistrements par "id"
adult34 = adult34.sort_values(by="id")
# regrouper les par "id", et pour chaque groupe remplacer les
# valeurs absentes par une valeur précédente dans le même groupe
adult34 = adult34.groupby("id").ffill()
# supprimer les enregistrements dupliqués
# on garde les derniers, puisqu'ils sont été réglés
adult34.drop_duplicates("id", keep="last", inplace=True)
Caractéristiques inutiles
Ici on va supprimer les colonnes inutiles:
- adult1.occupation
- adult34.id
adult1.drop(["occupation"], axis=1, inplace=True)
adult34.drop(["id"], axis=1, inplace=True)
Conflits de valeurs
Remplacer les valeurs de “marital-status” dans les tables “adult1” et “adult2” comme suit:
- “Never-married” par “single”
- “Married-civ-spouse”, “Married-spouse-absent” et “Married-AF-spouse” par “married”
- “Divorced” et “Separated” par “divorced”
- “Widowed” par “widowed”
dic = {
"Never-married": "single",
"Married-civ-spouse": "married",
"Married-spouse-absent": "married",
"Married-AF-spouse": "married",
"Divorced": "divorced",
"Separated": "divorced",
"Widowed": "widowed"
}
adult1["marital-status"] = adult1["marital-status"].map(dic)
adult2["marital-status"] = adult2["marital-status"].map(dic)
On va remplacer les valeurs de “sex” dans la table “adult1”: (Female, Male) par (F, M) respectivement. Vous pouvez vérifier les valeurs possibles pour cette colonne en utilisant la fonction pandas.Series.unique:
print adult1["marital-status"].unique()
print adult2["marital-status"].unique()
print adult34["marital-status"].unique()
ça va donner le résulat suivant:
['Male' 'Female' nan]
['F' 'M' 'Private, HS-grad' nan]
[u'M' u'F']
Ceci est dû au problème rencontré lors du chargement du fichier “adult2.csv” (les colonnes séparées par des virgules or elles doivent être séparées par des points-virgules). On laisse ça puisqu’on va nettoyer les enregistrements avec des champs vides. Sinon, on peut appliquer la même chose que sur “adult1” pour avoir des “NaN” là où il y a un problème.
adult1["sex"] = adult1["sex"].map({"Female": "F", "Male": "M"})
On va remplacer les valeurs de “class” dans la table “adult1”: (<=50K, >50K) par (N, Y) respectivement.
adult1["class"] = adult1["class"].map({"<=50K": "N", ">50K": "Y"})
Fusionnement des schémas
adult = pandas.concat([adult1, adult2, adult34], ignore_index=True)
II-6-3 Nétoyage des données
Avant tout, on va vérifier le nombre des valeurs indéfinies dans chaque colonne.
print adult.isnull().sum()
ça va donner
age 5
workclass 10
education 1
marital-status 4
sex 2
hours-per-week 2
class 0
dtype: int64
On va, donc, nettoyer tous les enregistrements avec une valeur “NaN” sauf la colonne “age”, on va la traiter autrement.
adult.dropna(subset=["workclass", "education", "marital-status", "sex", "hours-per-week", "class"], inplace=True)
Pour les valeurs de absentes de “age”, on va faire un lissage par moyenne:
- Transformer les valeurs de “age” comme numériques
- On regroupe les enregistrements par “class” et “education”. Ceci en supposant que les individus avec la même classe et le même niveau d’éducation ont le même age. Si on veut être plus sûr, on peut tracer des graphes entre “age” et les autres attributs.
- On calcule la moyenne et l’arrondir
- On l’affecte aux valeurs indéfinies
adult["age"] = pandas.to_numeric(adult["age"])
adult["age"] = adult.groupby(["class", "education"])["age"].transform(lambda x: x.fillna(int(round(x.mean()))))
On vérifie le nombre des valeurs indéfinies pour être sûre qu’il ne reste aucune. Aussi, les types des attributs; par exemple, “hours-per-week” doit être numérique et pas un objet.
adult["hours-per-week"] = pandas.to_numeric(adult["hours-per-week"])
II-6-4 Discrétisation
II-6-5 Mise à l’échelle min-max
II-6-6 Coupure
II-6-7 Mise à l’échelle log
II-6-8 Z-score
II-6-9 Binarisation
Bibliographie
- https://developers.google.com/machine-learning/data-prep/
- https://developers.google.com/machine-learning/crash-course/representation/video-lecture
- https://machinelearningmastery.com/how-to-prepare-data-for-machine-learning/
- https://www.altexsoft.com/blog/datascience/preparing-your-dataset-for-machine-learning-8-basic-techniques-that-make-your-data-better/
- https://www.analyticsindiamag.com/get-started-preparing-data-machine-learning/
- https://docs.microsoft.com/fr-fr/azure/machine-learning/team-data-science-process/prepare-data
- https://www.simplilearn.com/data-preprocessing-tutorial
- https://pandas.pydata.org/pandas-docs/stable/io.html
- https://www.kdnuggets.com/2018/05/data-labeling-machine-learning.html
- http://www.ml.ist.i.kyoto-u.ac.jp/wp/wp-content/uploads/2015/05/PAKDD2015_kashima.pdf
- https://www.kdnuggets.com/2017/06/7-techniques-handle-imbalanced-data.html